
Logistic分布指当n趋向于无穷大时,从指数分布(exponential distribution)中抽取的容量n的随机样本的最大与最小样本值的平均的极限分布。密度函式为:f(x)=exp[-(x-α)/β]/β{1+exp[-(x-α)/β]}2,-∞<x<∞,β>0,分布函式为:1/f(x)=exp[-(x-α)/β]。位置参数α为均值。分布的方差为π2β2/3,它的偏斜度为0,峰度为4.2。α=o,β=1时为标準logistic分布(standard logistic distribution),它的累积机率分布函式(cumulative distribution function)F(x)与机率分布f(x)之间满足:f(x)=F(x)[1-F(x)]。
基本介绍
- 中文名:Logistic分布
- 外文名:Logistic Distribution
- 别名:罗吉斯蒂克分布
- 所属学科:数学(数理统计)
- 相关概念:Logistic函式等
基本介绍
定义一
如果一个随机变数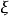 ,它的分布函式为
,它的分布函式为
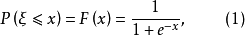
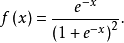
 图1a logistic分布函式
图1a logistic分布函式 图1b logistic密度函式
图1b logistic密度函式由图可见的期望值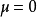 ,密度函式对对称。分布函式F(x)在处等于005。(0,0,5)为曲线F(x)的对称点,而F(x)=0及F(x)=1为其渐近线。在(0,0,5)点处F(x)的斜率m=0.25。这是logistic函式的最简单的形式。
,密度函式对对称。分布函式F(x)在处等于005。(0,0,5)为曲线F(x)的对称点,而F(x)=0及F(x)=1为其渐近线。在(0,0,5)点处F(x)的斜率m=0.25。这是logistic函式的最简单的形式。
定义二
Logistic分布函式为
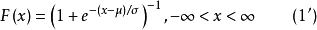
其中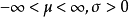 。
。
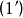
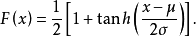
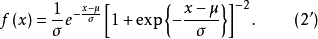
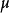
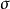
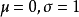
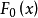
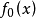
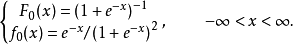
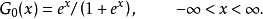
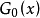
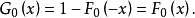
因此有时上也从出发,以它作为标準分布,经随机变数线性变换后导出的分布作为一般的Logistic分布。
一元logistic函式
一般地,一元logistic函式可表为
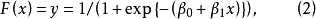
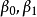
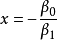
多元logistic函式
更一般的logistic函式为多元的(设为m元)
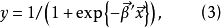
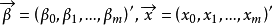
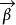
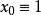
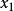
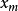
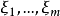
在研究来自同一总体的两个变数(设为X和Y)间的关係时,採得容量为n的样本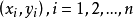 。画出这组数据的散点图,如曲线接近S形,可试用logistic曲线去拟合它。
。画出这组数据的散点图,如曲线接近S形,可试用logistic曲线去拟合它。
Logistic回归模型
模型概念
Logistic回归模型是分析二分类型变数时常用的非线性统计模型,是最重要且套用最广泛的非线性模型之一。该模型的因变数为二分类变数(y=0或y=1),结果变数与自变数间是非线性关係。形式如方程(1):
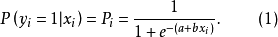
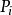
模型优缺点
优点:
第一,对变数要求低,可以接受非常态分配的数据;
第二,总体预测準确率较高;
第三,数据来源直接,操作简便;
第四,判断标準明确;
第五,模型稳定,利于推广创新。
缺点:
第一,大多数时候对ST企业预测準确率较低;
第二,P值临界点的选择影响模型预测结果;
第三,违约样本与正常样本的比例影响预测结果。
模型原理
模型构造的原理简单来说是运用对数运算将事件发生与否(即事件发生机率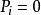 或1)与自变数x间的非线性关係转化为线性关係。以单一自变数为例,具体转化步骤如下:
或1)与自变数x间的非线性关係转化为线性关係。以单一自变数为例,具体转化步骤如下:
第一步,将上述Logistic模型方程(1)转化为如下一个非线性方程(2)。
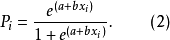
第二步,方程(2)化简转化为如下方程(3)。
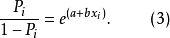
第三步,方程(3)等式两边同时取对数转化为如下方程(4)。
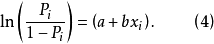
模型(4)得出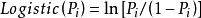 与x间的线性关係方程。
与x间的线性关係方程。
此时,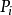 与
与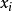 虽然不存线上性关係,但是关于P的函式记作logistic(Pi)与存线上性关係。同理,自变数可拓展为m个,则有如下模型方程(5)。
虽然不存线上性关係,但是关于P的函式记作logistic(Pi)与存线上性关係。同理,自变数可拓展为m个,则有如下模型方程(5)。
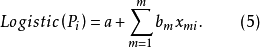
以上得到的模型同样可以用来预测事件的发生。预测时根据已知自变数与模型方程得出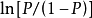 ,可以进一步计算事件发生的机率P。P处于0与1之间,越接近1表示发生的机率越大。
,可以进一步计算事件发生的机率P。P处于0与1之间,越接近1表示发生的机率越大。
模型基本假设
第一,数据必须来自随机样本;
第二,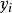 为m个自变数
为m个自变数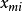 的函式;
的函式;
第三,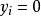 或1;
或1;
第四,自变数不需要呈常态分配。
模型套用步骤
第一步,选取样本、确定初始指标;
第二步,筛选指标;
运用SPSS软体对所有指标进行Kolmogorov-Smirnov常态分配检验。符合常态分配的指标进行显着性T检验,不符合常态分配的数据进行Mann-Whitney显着性检验,去除不显着指标。进行Pearson检验,去除与其他指标存在高度相关性的指标。进行多重共线性检验,去除与其他指标存在多重共线性的指标;
第三步,进行KMO检验,确定是否进行因子分析;
第四步,进行Logistic回归,得到模型,观察模型拟合程度及预测準确率;
第五步,用检验样本检验模型预测能力;
第六步,利用模型预测事件的发生机率。
模型参数解释
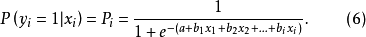
当参数b大于0时,自变数x增大,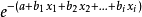 减小,增大;
减小,增大;
当参数b小于0时,自变数x增大,增大,减小;
当参数b等于0时,自变数x增加对无影响,不变。
因此,模型参量係数可以反映自变数x与事件发生机率P的关係。係数为正表明自变数x的增长促进事件的发生,係数为负表明自变数x的增长抑制事件的发生。
















