
线性估计(linear estimation)是随机过程理论的一个重要的实际套用问题。是由已知随机变数族{X(t),tET}的观测值在某个最优準则下估计未知随机变数Y的值.即寻找一个{X(t),tET}的函式f (X(t) ,tET),使得Y-f (X(t),tET)最优地近似Y。若f限于线性函式类时,这问题称为线性估计。
基本介绍
- 中文名:线性估计
- 外文名:nonlinear estimation
- 学科:数学
线性估计模型
线性估计的模型为:
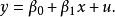
x是解释变数(自变数);
B0和B1是待估计的参数。
估计方法
LS既是最小方差,以此作为目标函式求解参数估计值的方法称为最小方差估计,SVD分解是目前解决这一问题的最有效手段。
WLS既是带权重的最小方差,其思想是将每个输入的样本赋予权值,初始时每个样本的权值相等,然后使用所有带权重的样本估计模型的参数,得到参数后,计算每个样本与模型的偏差,再根据偏差决定样本的新权重,偏差越大则权重越小,然后重複模型参数估计与权重更新这个过程,直到样本的带权偏差和收敛为止。
Ransac是一种随机参数估计算法。Ransac LS从样本中随机抽选出一个样本子集,使用LS对这个子集计算模型参数,然后计算所有样本与该模型的偏差,再使用一个预先设定好的阈值与偏差比较,当偏差小于阈值时,该样本点属于模型内样本点(inliers),否则为模型外样本点(outliers),记录下当前的inliers的个数,然后重複这一过程。每一次重複,都记录当前最佳的模型参数,所谓最佳,既是inliers的个数最多,此时对应的inliers个数为best_ninliers。每次叠代的末尾,都会根据期望的误差率、best_ninliers、总样本个数、当前叠代次数,计算一个叠代结束评判因子,据此决定是否叠代结束。叠代结束后,最佳模型参数就是最终的模型参数估计值。
LMedS也是一种随机参数估计算法。LMedS也从样本中随机抽选出一个样本子集,使用LS对子集计算模型参数,然后计算所有样本与该模型的偏差。但是与Ransac LS不同的是,LMedS记录的是所有样本中,偏差值居中的那个样本的偏差,称为Med偏差(这也是LMedS中Med的由来),以及本次计算得到的模型参数。由于这一变化,LMedS不需要预先设定阈值来区分inliers和outliers。重複前面的过程N次,从中N个Med偏差中挑选出最小的一个,其对应的模型参数就是最终的模型参数估计值。其中叠代次数N是由样本集子中样本的个数、期望的模型误差、事先估计的样本中outliers的比例所决定。
WLS既是带权重的最小方差,其思想是将每个输入的样本赋予权值,初始时每个样本的权值相等,然后使用所有带权重的样本估计模型的参数,得到参数后,计算每个样本与模型的偏差,再根据偏差决定样本的新权重,偏差越大则权重越小,然后重複模型参数估计与权重更新这个过程,直到样本的带权偏差和收敛为止。
Ransac是一种随机参数估计算法。Ransac LS从样本中随机抽选出一个样本子集,使用LS对这个子集计算模型参数,然后计算所有样本与该模型的偏差,再使用一个预先设定好的阈值与偏差比较,当偏差小于阈值时,该样本点属于模型内样本点(inliers),否则为模型外样本点(outliers),记录下当前的inliers的个数,然后重複这一过程。每一次重複,都记录当前最佳的模型参数,所谓最佳,既是inliers的个数最多,此时对应的inliers个数为best_ninliers。每次叠代的末尾,都会根据期望的误差率、best_ninliers、总样本个数、当前叠代次数,计算一个叠代结束评判因子,据此决定是否叠代结束。叠代结束后,最佳模型参数就是最终的模型参数估计值。
LMedS也是一种随机参数估计算法。LMedS也从样本中随机抽选出一个样本子集,使用LS对子集计算模型参数,然后计算所有样本与该模型的偏差。但是与Ransac LS不同的是,LMedS记录的是所有样本中,偏差值居中的那个样本的偏差,称为Med偏差(这也是LMedS中Med的由来),以及本次计算得到的模型参数。由于这一变化,LMedS不需要预先设定阈值来区分inliers和outliers。重複前面的过程N次,从中N个Med偏差中挑选出最小的一个,其对应的模型参数就是最终的模型参数估计值。其中叠代次数N是由样本集子中样本的个数、期望的模型误差、事先估计的样本中outliers的比例所决定。