")
迪杰斯特拉算法(Dijkstra)是由荷兰计算机科学家狄克斯特拉于1959 年提出的,因此又叫狄克斯特拉算法。是从一个顶点到其余各顶点的最短路径算法,解决的是有权图中最短路径问题。迪杰斯特拉算法主要特点是以起始点为中心向外层层扩展,直到扩展到终点为止。
基本介绍
- 中文名:迪克斯特拉算法
- 外文名:Dijkstra's Algorithm
- 分类:计算机算法
- 用途:单源最短路径问题
定义
Dijkstra算法一般的表述通常有两种方式,一种用永久和临时标号方式,一种是用OPEN, CLOSE表的方式,这里均採用永久和临时标号的方式。注意该算法要求图中不存在负权边。
原理
1.首先,引入一个辅助数组(vector)D,它的每个元素D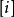 表示当前所找到的从起始点
表示当前所找到的从起始点 (即源点 )到其它每个顶点
(即源点 )到其它每个顶点 的长度。
的长度。 Dijkstra算法运行动画过程
Dijkstra算法运行动画过程
Dijkstra算法运行动画过程例如,D[3] = 2表示从起始点到顶点3的路径相对最小长度为2。这里强调相对就是说在算法执行过程中D的值是在不断逼近最终结果但在过程中不一定就等于长度。
2.D的初始状态为:若从 到 有弧(即从 到 存在连线边),则D 为弧上的权值(即为从 到 的边的权值);否则置D 为∞。
显然,长度为 D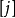 = Min{ D | ∈V } 的路径就是从 出发到顶点
= Min{ D | ∈V } 的路径就是从 出发到顶点 的长度最短的一条路径,此路径为(
的长度最短的一条路径,此路径为(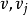 )。
)。
3.那幺,下一条长度次短的是哪一条呢?也就是找到从源点 到下一个顶点的最短路径长度所对应的顶点,且这条最短路径长度仅次于从源点 到顶点 的最短路径长度。
假设该次短路径的终点是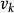 ,则可想而知,这条路径要幺是(
,则可想而知,这条路径要幺是(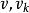 ),或者是(
),或者是( )。它的长度或者是从 到 的弧上的权值,或者是D 加上从
)。它的长度或者是从 到 的弧上的权值,或者是D 加上从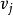 到 的弧上的权值。
到 的弧上的权值。
4.一般情况下,假设S为已求得的从源点 出发的最短路径长度的顶点的集合,则可证明:下一条次最短路径(设其终点为 )要幺是弧(
)要幺是弧( ),或者是从源点 出发的中间只经过S中的顶点而最后到达顶点 的路径。
),或者是从源点 出发的中间只经过S中的顶点而最后到达顶点 的路径。
因此,下一条长度次短的的最短路径长度必是D = Min{ D | ∈V-S },其中D 要幺是弧(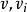 )上的权值,要幺是D
)上的权值,要幺是D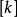 ( ∈S)和弧( , )上的权值之和。
( ∈S)和弧( , )上的权值之和。
算法描述如下:
1)令arcs表示弧上的权值。若弧不存在,则置arcs为∞(在本程式中为MAXCOST)。S为已找到的从 出发的的终点的集合,初始状态为空集。那幺,从 出发到图上其余各顶点 可能达到的长度的初值为D=arcs[Locate Vex(G, )], ∈V;
2)选择 ,使得D =Min{ D | ∈V-S } ;
3)修改从 出发的到集合V-S中任一顶点 的最短路径长度。
问题描述
在有向图 G=(V,E) 中,假设每条边 E[i] 的长度为 w[i],找到由顶点 V0 到其余各点的最短值。
算法思想
按路径长度递增次序产生算法:
把顶点集合V分成两组:
(1)S:已求出的顶点的集合(初始时只含有源点V0)
(2)V-S=T:尚未确定的顶点集合
将T中顶点按递增的次序加入到S中,保证:
(1)从源点V0到S中其他各顶点的长度都不大于从V0到T中任何顶点的最短路径长度
(2)每个顶点对应一个距离值
S中顶点:从V0到此顶点的长度
T中顶点:从V0到此顶点的只包括S中顶点作中间顶点的最短路径长度
依据:可以证明V0到T中顶点Vk的,或是从V0到Vk的直接路径的权值;或是从V0经S中顶点到Vk的路径权值之和
(反证法可证)
求最短路径步骤
算法步骤如下:
G={V,E}
1. 初始时令 S={V0},T=V-S={其余顶点},T中顶点对应的距离值
若存在<V0,Vi>,d(V0,Vi)为<V0,Vi>弧上的权值
若不存在<V0,Vi>,d(V0,Vi)为∞
2. 从T中选取一个与S中顶点有关联边且权值最小的顶点W,加入到S中
3. 对其余T中顶点的距离值进行修改:若加进W作中间顶点,从V0到Vi的距离值缩短,则修改此距离值
重複上述步骤2、3,直到S中包含所有顶点,即W=Vi为止
算法实现
pascal语言
下面是该算法的Pascal程式
typebool=array[1..10]ofboolean;arr=array[0..10]ofinteger;vara:array[1..10,1..10]ofinteger;//存储图的邻接数组,无边为10000c,d,e:arr;//c为最短路径数值,d为各点前趋,t:bool;//e:路径,t为辅助数组i,j,n,m:integer;inf,outf:text;procedure init;//不同题目邻接数组建立方式不一样begin assign(inf,inputfile); assign(outf,outputfile); reset(inf); rewrite(outf); read(inf,n); for i:= 1 to n do begin for j := 1 to n do begin read(inf,a[i,j]); if a[i,j]=0 then a[i,j]:=10000; end; end; end;procedure dijkstra(qi:integer;t:bool;varc{,d}:arr);//qi起点,{}中为求路径部分,不需求路径时可以不要vari,j,k,min:integer;begin t[qi]:=true;//t数组一般在调用前初始,除起点外所有节点都化成false,也可将部分点初始化成true以迴避这些点 for i:= 1 to n do d[i] := qi; d[qi]:=0; for i:=1 to n do c[i]:=a[qi,i]; for i:= 1 to n-1 do begin min:=maxint;//改为最大值 for j:=1 to n do if(c[j]<min) and not t[j] then begin k:=j; min:=c[j]; end; t[k]:=true; for j:=1 to n do if(c[k]+a[k,j]<c[j]) and not t[j] then begin c[j]:=c[k]+a[k,j]; d[j]:=k; end; end;end; procedure make(zh:integer;d:arr;vare:arr);//生成路径,e[0]保存路径vari,j,k:integer;//上的节点个数begin i:=0; while d[zh]<>0 do begin inc(i); e[i]:=zh; zh:=d[zh]; end; inc(i); e[i]:=qi; e[0]:=i;end;主程式调用:求长度:初始化t,然后dijkstra(qi,t,c,d)
求路径:make(m,d,e) ,m是终点
C语言
下面是该算法的C语言实现
#include<stdio.h>#include<stdlib.h>#define max1 10000000 //原词条这里的值太大,导致溢出,后面比较大小时会出错int a[1000][1000];int d[1000];//d表示源节点到该节点的最小距离int p[1000];//p标记访问过的节点int i, j, k;int m;//m代表边数int n;//n代表点数int main(){ scanf("%d%d",&n,&m); int min1; int x,y,z; for(i=1;i<=m;i++) { scanf("%d%d%d",&x,&y,&z); a[x][y]=z; a[y][x]=z; } for( i=1; i<=n; i++) d[i]=max1; d[1]=0; for(i=1;i<=n;i++) { min1 = max1; //下面这个for循环的功能类似冒泡排序,目的是找到未访问节点中d[j]值最小的那个节点, //作为下一个访问节点,用k标记 for(j=1;j<=n;j++) if(!p[j]&&d[j]<min1) { min1=d[j]; k=j; } //p[k]=d[k]; // 这是原来的代码,用下一 条代码替代。初始时,执行到这里k=1,而d[1]=0 //从而p[1]等于0,这样的话,上面的循环在之后的每次执行之后,k还是等于1。 p[k] = 1; //置1表示第k个节点已经访问过了 for(j=1;j<=n;j++) if(a[k][j]!=0&&!p[j]&&d[j]>d[k]+a[k][j]) d[j]=d[k]+a[k][j]; } //最终输出从源节点到其他每个节点的最小距离 for(i=1;i<n;i++) printf("%d->",d[i]); printf("%d\n",d[n]); return 0;}大学经典教材<<数据结构>>(C语言版 严蔚敏 吴为民 编着) 中该算法的实现
/*测试数据 教科书 P189 G6 的邻接矩阵 其中 数字 1000000 代表无穷大61000000 1000000 10 100000 30 1001000000 1000000 5 1000000 1000000 10000001000000 1000000 1000000 50 1000000 10000001000000 1000000 1000000 1000000 1000000 101000000 1000000 1000000 20 1000000 601000000 1000000 1000000 1000000 1000000 1000000结果:D[0] D[1] D[2] D[3] D[4] D[5] 0 1000000 10 50 30 60*/#include <iostream>#include <cstdio>#define MAX 1000000using namespace std;int arcs[10][10];//邻接矩阵int D[10];//保存最短路径长度int p[10][10];//路径int final[10];//若final[i] = 1则说明 顶点vi已在集合S中int n = 0;//顶点个数int v0 = 0;//源点int v,w;void ShortestPath_DIJ(){ for (v = 0; v < n; v++) //循环 初始化 { final[v] = 0; D[v] = arcs[v0][v]; for (w = 0; w < n; w++) p[v][w] = 0;//设空路径 if (D[v] < MAX) {p[v][v0] = 1; p[v][v] = 1;} } D[v0] = 0; final[v0]=1; //初始化 v0顶点属于集合S //开始主循环 每次求得v0到某个顶点v的最短路径 并加v到集合S中 for (int i = 1; i < n; i++) { int min = MAX; for (w = 0; w < n; w++) { //我认为的核心过程--选点 if (!final[w]) //如果w顶点在V-S中 { //这个过程最终选出的点 应该是选出当前V-S中与S有关联边 //且权值最小的顶点 书上描述为 当前离V0最近的点 if (D[w] < min) {v = w; min = D[w];} } } final[v] = 1; //选出该点后加入到合集S中 for (w = 0; w < n; w++)//更新当前最短路径和距离 { /*在此循环中 v为当前刚选入集合S中的点 则以点V为中间点 考察 d0v+dvw 是否小于 D[w] 如果小于 则更新 比如加进点 3 则若要考察 D[5] 是否要更新 就 判断 d(v0-v3) + d(v3-v5) 的和是否小于D[5] */ if (!final[w] && (min+arcs[v][w]<D[w])) { D[w] = min + arcs[v][w]; // p[w] = p[v]; p[w][w] = 1; //p[w] = p[v] + [w] } } }}int main(){ cin >> n; for (int i = 0; i < n; i++) { for (int j = 0; j < n; j++) { cin >> arcs[i][j]; } } ShortestPath_DIJ(); for (int i = 0; i < n; i++) printf("D[%d] = %d\n",i,D[i]); return 0;}堆最佳化
思考
该算法複杂度为n^2,我们可以发现,如果边数远小于n^2,对此可以考虑用堆这种数据结构进行最佳化,取出最短路径的複杂度降为O(1);每次调整的複杂度降为O(elogn);e为该点的边数,所以複杂度降为O((m+n)logn)。
实现
1. 将源点加入堆,并调整堆。
2. 选出堆顶元素u(即代价最小的元素),从堆中删除,并对堆进行调整。
3. 处理与u相邻的,未被访问过的,满足三角不等式的顶点
1):若该点在堆里,更新距离,并调整该元素在堆中的位置。
2):若该点不在堆里,加入堆,更新堆。
4. 若取到的u为终点,结束算法;否则重複步骤2、3。
Java代码
//visit初始为0,防止回溯int visit[] = new int[n+1];//假设起点为src, 终点为dst, 图以二维矩阵的形式存储,若graph[i][j] == 0, 代表i,j不相连int Dijkstra(int src, int dst, int[][] graph){ PriorityQueue<Node> pq = new PriorityQueue<Node>(); //将起点加入pq pq.add(new Node(src, 0)); while(pq.size()){ Node t = pq.poll(); //当前节点是终点,即可返回最短路径 if(t.node == dst) return t.cost; //若当前节点已遍历过,跳过当前节点 if(visit[t.node]) continue; //将当前节点标记成已遍历 visit[t.node] = 1; for(int i = 0; i < n; i++){ if(graph[t.node][i] && !visited[i]){ pq.add(new Node(i, t.cost + graph[t.node][i])); } } } return -1}//定义一个存储节点和离起点相应距离的数据结构class Node implements Comparator<Node> { public int node; public int cost; public Node() { } public Node(int node, int cost) { this.node = node; this.cost = cost; } @Override public int compare(Node node1, Node node2) { if (node1.cost < node2.cost) return -1; if (node1.cost > node2.cost) return 1; return 0; }}