
归一化特徵是数据挖掘的一项基础工作,不同评价指标往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,为了消除指标之间的量纲影响,需要进行数据标準化处理,以解决数据指标之间的可比性。原始数据经过数据标準化处理后,各指标处于同一数量级,适合进行综合对比评价。
基本介绍
- 中文名:归一化特徵
- 外文名:Normalized feature
背景
该问题的出现是因为我们没有同等程度的看待各个特徵,即我们没有将各个特徵量化到统一的区间。比如对房屋售价进行预测时,我们的特徵仅有房屋面积一项,但是,在实际生活中,卧室数目也一定程度上影响了房屋售价。下面,我们有这样一组训练样本(图一):
 图一
图一注意到,房屋面积及卧室数量两个特徵在数值上差异巨大,如果直接将该样本送入训练,则代价函式的轮廓会是“扁长的”,在找到最优解前,梯度下降的过程不仅是曲折的,也是非常耗时的(图二):
 图二
图二常用方法
Standardization
Standardization又称为Z-score normalization,量化后的特徵将服从标準常态分配:
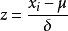
其中,u和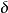 分别为对应特徵的均值和标準差。
分别为对应特徵的均值和标準差。
Min-Max Scaling
Min-Max Scaling又称为Min-Max normalization, 特徵量化的公式为:
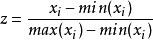
量化后的特徵将分布在区间。
大多数机器学习算法中,会选择Standardization来进行特徵缩放,但是,Min-Max Scaling也并非会被弃置一地。在数字图像处理中,像素强度通常就会被量化到[0,1]区间,在一般的神经网路算法中,也会要求特徵被量化[0,1]区间。
进行了特徵缩放以后,代价函式的轮廓会是“偏圆”的,梯度下降过程更加笔直,收敛更快性能因此也得到提升(图三):
 图三
图三代码实现
def standardize(X): """特徵标準化处理 Args: X: 样本集 Returns: 标準后的样本集 """ m, n = X.shape # 归一化每一个特徵 for j in range(n): features = X[:,j] meanVal = features.mean(axis=0) std = features.std(axis=0) if std != 0: X[:, j] = (features-meanVal)/std else X[:, j] = 0 return X def normalize(X): """Min-Max normalization sklearn.preprocess 的MaxMinScalar Args: X: 样本集 Returns: 归一化后的样本集 """ m, n = X.shape # 归一化每一个特徵 for j in range(n): features = X[:,j] minVal = features.min(axis=0) maxVal = features.max(axis=0) diff = maxVal - minVal if diff != 0: X[:,j] = (features-minVal)/diff else: X[:,j] = 0 return X</span>