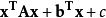在机器学习领域,分类的目标是指将具有相似特徵的对象聚集。而一个线性分类器则透过特徵的线性组合来做出分类决定,以达到此种目的。对象的特徵通常被描述为特徵值,而在向量中则描述为特徵向量。
基本介绍
- 中文名:线性分类器
- 外文名:Linear classifier
- 目标:具有相似特徵的对象聚集
- 学科:人工智慧
定义
如果输入的特徵向量是实数向量 ,则输出的分数为:
,则输出的分数为:
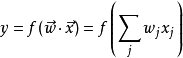
其中 是一个权重向量,而f是一个函式,该函式可以通过预先定义的功能块,映射两个向量的点积,得到希望的输出。权重向量
是一个权重向量,而f是一个函式,该函式可以通过预先定义的功能块,映射两个向量的点积,得到希望的输出。权重向量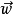 是从带标籤的训练样本集合中所学到的。通常,"f"是个简单函式,会将超过一定阈值的值对应到第一类,其它的值对应到第二类。一个比较複杂的"f"则可能将某个东西归属于某一类。
是从带标籤的训练样本集合中所学到的。通常,"f"是个简单函式,会将超过一定阈值的值对应到第一类,其它的值对应到第二类。一个比较複杂的"f"则可能将某个东西归属于某一类。
对于一个二元分类问题,可以构想成是将一个线性分类利用超平面划分高维空间的情况: 在超平面一侧的所有点都被分类成"是",另一侧则分成"否"。
作为最快分类器,线性分类器通常套用于对分类速度有较高要求的情况下,特别是当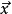 为稀疏向量时。虽然如此,决策树可以更快。此外,当 的维度很大时,线形分类器通常表现良好。如文本分类时,传统上, 中的一个元素是文章所使用到的某个辞彙的出现的次数。在这种情况下,分类器应被适当地正则化。
为稀疏向量时。虽然如此,决策树可以更快。此外,当 的维度很大时,线形分类器通常表现良好。如文本分类时,传统上, 中的一个元素是文章所使用到的某个辞彙的出现的次数。在这种情况下,分类器应被适当地正则化。
生成模型与判别模型
有两种类型用来决定 的线性分类器。第一种模型条件机率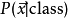 。这类的算法包括:
。这类的算法包括:
- 线性判别分析(LDA) --- 假设为高斯条件密度模型。
- 朴素贝叶斯分类器--- 假设为条件独立性假设模型。
第二种方式则称为判别模型(discriminative models),这种方法是试图去最大化一个训练集(training set)的输出值。在训练的成本函式中有一个额外的项加入,可以容易地表示正则化。例子包含:
- Logit模型---的最大似然估计,其假设观察到的训练集是由一个依赖于分类器的输出的二元模型所产生。
- 感知元(Perceptron) --- 一个试图去修正在训练集中遇到错误的算法。
- 支持向量机--- 一个试图去最大化决策超平面和训练集中的样本间的边界(margin)的算法。
判别训练通常会比模型化条件密度函式产生较高的準确。然而,在处理遗失资料时,使用条件密度模型通常是更为简单的。
所有以上所列线性分类器算法,只要使用kernel trick都可被转成在另一个向量空间的非线性算法。
二次分类器
二次分类器是在机器学习中,使用二次曲面来将物件或事件分成两个或以上的分类。 它是线性分类器的一般化版本。
统计分类考虑一个集合,每一个元素是一个对物件或事件观察后所得的向量x,每一个都被分成y。 这个集合一般被称为训练资料。 问题是在于,要如何决定一个新的观察项目其最好的类别应是哪一种。 对一个二次分类器,它假设其解会成二次关係,所以y是由以下来决定: