
中误差是衡量观测精度的一种数字标準,亦称“标準差”或“均方根差”。在相同观测条件下的一组真误差平方中数的平方根。因真误差不易求得,所以通常用最小二乘法求得的观测值改正数来代替真误差。它是观测值与真值偏差的平方和观测次数n比值的平方根。
中误差不等于真误差,它仅是一组真误差的代表值。中误差的大小反映了该组观测值精度的高低,因此,通常称中误差为观测值的中误差。
基本介绍
- 中文名:中误差
- 外文名:root mean square error;RMSE
- 别名:标準差”或“均方根差”
- 定义:衡量观测精度的一种数字标準
- 代替值:真值只能用最或然值
- 性质:描述代数误差
- 方法:最小二乘法
- 计算:观测值与真值偏差平方和
採用原因
代替值
在实际测量中,观测次数n总是有限的,真值只能用最或然值(常用多次观测的平均值)来代替。
标準差
标準差(Standard Error)是方差(Variance)的平方根,对一组测量中的特大或特小误差反映非常敏感,能够很好地反映出测量结果波动大小。这正是标準差在工程测量中广泛被採用的原因。
产生原因
由某种固定的原因造成的,使测定结果偏高或偏低,重複测定时会重複出现,系统误差的大小几乎是一个恆定值,因而又被称之为恆定误差或可测误差。它产生的原因有以下几点:
系统误差
由某种固定的原因造成的,使测定结果偏高或偏低,重複测定时会重複出现,系统误差的大小几乎是一个恆定值,因而又被称之为恆定误差或可测误差。它产生的原因有以下几点:
仪器误差:仪器本身不够精度或未经校正所引起的,如天平、砝码和量器刻度不够準确。为避免引起仪器误差,我们应对所使用的量器及天平进行校正。
试剂误差:由于试剂不纯或蒸馏水中含有微量杂质所引起的误差。消除方法可进行空白实验,在不加试样的情况下,按照被测试样的分析步骤和条件进行分析,得到的结果为空白值,从试样的分析结果中减去“空白值”就可以得到更接近真实含量的分析结果。
方法误差:这种误差是由于分析方法本身所造成的。如重量分析时,由于沉澱的溶解造成损失或因吸附某些杂质而产生误差;或滴定分析中,因为反应不完全或干扰离子的影响,以及滴定终点和等当点不符合等。
操作误差:正常操作条件下,由于分析人员掌握操作规程与正确控制条件稍有出入而引起的误差。如滴定管读数时偏高或偏低,对某种颜色的变化辨别不够敏锐等所造成的误差。
偶然误差
偶然误差也称不定误差,它是由某些偶然因素:测定时环境的温度、湿度气压的微小波动,或由于外界条件的影响而使安放在操作台上的天平受到微小的震动所引起的。其影响有时大、有时小。因而偶然误差难以察觉,也难以控制。
随着测定次数的增加偶然误差的算术平均值将逐渐接近于零。因而有必要时,应多次测定 ,但并非实验次数越多越好,这样只浪费更多的人力、物力。一般测定中,做2~3次平行测定可达到不超过规定误差的目的。
粗差
粗差即粗大误差,是指比在正常观测条件下所可能出现的最大误差还要大的误差,通俗地说,粗差要比偶然误差大上好几倍。例如观测时大数读错,计算机输入数据错误,航测像片判读错误,控制网起始数据错误等。这种错误或误差,在一定程度上可以避免。但在使用现今的测量技术如全球定位系统(GPS)、地理信息系统(GIS)、遥感(RS)以及其他高精度的自动化数据採集中,经常是粗差混入信息之中,识别粗差源并不是简单方法可以达到目的的,需要通过数据处理方法进行识别和消除其影响。
计算公式
测量误差按其对测量结果影响的性质,可分为:
一.系统误差(system error)
1.定义:在相同观测条件下,对某量进行一系列观测,如误差出现符号和大小均相同或按一定的规律变化,这种误差称为系统误差。
2.特点:具有积累性,对测量结果的影响大,但可通过一般的改正或用一定的观测方法加以消除。
二.偶然误差(accident error)
1.定义:在相同观测条件下,对某量进行一系列观测,如误差出现符号和大小均不一定,这种误差称为偶然误差。但具有一定的统计规律。
2.特点:
(1) 具有一定的範围。
(2) 绝对值小的误差出现机率大。
(3) 绝对值相等的正、负误差出现的机率相同。
(4) 数学期限望等于零。即:
误差机率分布曲线呈常态分配,偶然误差要通过的一定的数学方法(测量平差)来处理。此外,在测量工作中还要注意避免粗差(gross error)(即:错误)的出现。
衡量指标
测量上常见的精度指标有:中误差、相对误差、极限误差。
一.中误差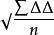 方差
方差
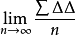
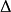
规律:标準差估值(中误差m)绝对值愈小,观测精度愈高。
在测量中,n为有限值,计算中误差m的方法,有:
1.用真误差(true error)来确定中误差——适用于观测量真值已知时。
真误差Δ——观测值与其真值之差,有:
标準差
中误差(标準差估值), n为观测值个数。
2.用改正数来确定中误差(白塞尔公式)——适用于观测量真值未知时。
V——最或是值与观测值之差。一般为算术平均值与观测值之差,即有:
二.相对误差
1.相对中误差
2.往返测较差率K
算法研究
研究背景
整合和更新来自不同来源、不同比例尺、不同时间段的表示同一地图目标的地理数据越来越引起人们的关注。空间面状地物和自然要素在很多地图表示中都占有很大的比例,可以用来表示房屋、土地利用、面状水体和植被等,它是地图表达和地图使用者关心的主要内容,本文主要讨论多尺度空间面实体的匹配。空间面实体数据主要有空间特徵和属性特徵,空间特徵主要包括几何特徵和拓扑特徵,几何特徵主要包括重心位置、中心位置、面积大小和边界,拓扑特徵主要包括面积重叠度、属性成分关联度;属性特徵主要是使用实体的属性信息。
空间面匹配,国外学者作过大量的研究。在几何匹配方面,文献提出面质心结合多种匹配检验规则的几何匹配方法,通过面实体栅格化后收缩来确定质心,然后将其矢量化,用点在面内的规则进行粗匹配,再结合多边形的面积A和面密度C进行匹配检验,最终判断匹配情况。文献通过匹配面的边界来计算边界的距离来检测不同时间点的空间面的明显不同,该方法适合于明确的边界的面数据,不适合于大量变化的地形数据。文献提出一种基于邻近关係确定面与面大致的关係,辅助Hausdorff距离来区分面之间的匹配关係,来确定面之间的共轭点,可以用来匹配面数据。语义信息主要取决于空间数据模型和属性数据模型,语义信息可以用来辅助匹配关係。文献提出一种基于知识的非空间属性数据匹配策略,通过计算属性项的相似度值以确定匹配实体。文献提出一种基于语义和结构的相似性的属性数据匹配方法,来匹配正式和非正式的地理数据。
国内学者也作了大量的工作,文献提出基于模糊拓扑关係分类的匹配方法,该方法计算形态距离比较麻烦,只适合于房屋等人工地物。文献在扩展文献的机率论匹配算法的基础上提出一种多準则融合算法,对于面数据,主要採用重心S和面的重叠度A指标,指标的权重是由专家经验来获取的。文献提出基于相似性的面实体匹配方法,该方法适合于相似比例尺的地图数据的匹配。文献提出了基于成分关联区域相似度的面实体模糊匹配算法,但模糊分类比较困难,不适合多比例尺数据。文献也提出一种基于几何特徵的多尺度的面实体匹配方法,这也是一种基于相似性的匹配方法,需要确定各个指标的权重。面匹配的算法还存在一些问题。首先,如何确定每个指标的阈值或者权重。需要确定的阈值主要有:缓冲区半径、Hausdorff距离、形态距离、属性相似性。指标的阈值
都与比例尺密切相关。机率匹配、相似性匹配虽然都不需要阈值,但是每个指标的权重在不同的比例尺下是不相同的,如何确定权重也是一个难点。面数据由点组成,利用点的精度信息来匹配空间数据,文献等首先使用点距离信息确定匹配,缓冲区大小根据地图的点位精度而定。文献也利用地图中点的误差来实现点的匹配,但是点位误差很难确定。其次,如何确定面的M∶N关係。大多都匹配算法都是基于文献提出的双向匹配策略,但是其方法只适合于点匹配。文献提出用面数据的邻近关係,利用聚集算法可以确定面与面数据之间的多对多的关係的大致关係,再根据Hausdorff距离确定数据之间的精确关係,该距离没有考虑多尺度情况下的匹配,需要统计数据才能确定範围。最后,很难确定数据匹配不确定性的範围,错误信息的範围对人工互动的过程有重要的影响。文献提出一种基于证据理论来匹配点目标,但是计算每个指标的信任度仍然是一个经验的过程。根据製图误差理论,中误差作为数据质量和地图综合的指标,而且其大小範围随着比例尺的变化而变化,可以有效地套用于多尺度空间数据的匹配,并可以确定数据不确定性的範围。本文在文献提出的邻近关係匹配的基础上,提出一种基于中误差和邻近关係的多尺度空间面实体匹配算法,不仅可以确定準确的数据範围,同时可以确定不确定性的匹配範围,同时考虑了不同比例尺下製图综合的影响,可以有效套用于多尺度面实体匹配。
都与比例尺密切相关。机率匹配、相似性匹配虽然都不需要阈值,但是每个指标的权重在不同的比例尺下是不相同的,如何确定权重也是一个难点。面数据由点组成,利用点的精度信息来匹配空间数据,文献等首先使用点距离信息确定匹配,缓冲区大小根据地图的点位精度而定。文献也利用地图中点的误差来实现点的匹配,但是点位误差很难确定。其次,如何确定面的M∶N关係。大多都匹配算法都是基于文献提出的双向匹配策略,但是其方法只适合于点匹配。文献提出用面数据的邻近关係,利用聚集算法可以确定面与面数据之间的多对多的关係的大致关係,再根据Hausdorff距离确定数据之间的精确关係,该距离没有考虑多尺度情况下的匹配,需要统计数据才能确定範围。最后,很难确定数据匹配不确定性的範围,错误信息的範围对人工互动的过程有重要的影响。文献提出一种基于证据理论来匹配点目标,但是计算每个指标的信任度仍然是一个经验的过程。根据製图误差理论,中误差作为数据质量和地图综合的指标,而且其大小範围随着比例尺的变化而变化,可以有效地套用于多尺度空间数据的匹配,并可以确定数据不确定性的範围。本文在文献提出的邻近关係匹配的基础上,提出一种基于中误差和邻近关係的多尺度空间面实体匹配算法,不仅可以确定準确的数据範围,同时可以确定不确定性的匹配範围,同时考虑了不同比例尺下製图综合的影响,可以有效套用于多尺度面实体匹配。
算法原理
(1)中误差
中误差是衡量观测精度的一种数字标準,亦称“标準差”或“均方根差”。它是观测值与真值偏差的平方和与观测次数n比值的平方根。点位误差表示点位的观测值与真值之差,製图规範中的点位误差用地物点和控制点的位置中误差来衡量。点位误差机率分布曲线呈常态分配或类常态分配。
点误差的大小通过中误差来衡量,其机率分布满足常态分配的点位误差表示99%以上的点都分布2倍中误差以内,中误差的大小随着数据源的不同而变化,但是传统的规範製图中规定同比例尺中误差的範围是固定的,该範围随着比例尺的变大而变大,中误差σ必须满足-σmax≤σ≤σmax。
(2)邻近关係
对于多对多匹配关係也是一个匹配的难点问题,引入邻近关係来完成面与面之间最终的匹配。M:N匹配实际上是一个聚类问题,表示分别用M面和N面来表示同一个地物目标。文献提出利用邻近关係来合併分散的面片,文献在此工作的基础上用面与面之间的叠置关係来确定面之间关係。前面可以通过计算中误差距离可以初步确定要素的对应关係,可以充分利用上一步匹配过滤之后的匹配成果来完成M:N匹配。对于原始要素S对应的候选集合的每个要素,可以反向搜寻每个候选要素的对应的叠置的集合,并将该要素添加到“源要素”集中,构建M要素集合和N要素集合,最终完成M:N匹配。
研究结论
本文根据製图误差理论,利用空间数据的中误差範围信息和数据邻近关係来匹配多尺度空间面实体数据。利用中误差信息可以有效地提高初始搜寻到準确率,首先确定1:0以及1:M关係,通过建立邻近关係矩阵来确定数据的多对多关係,并通过扩大範围确定相对低一些的信任度的匹配关係,接着将这些关係进行人工互动处理,最终完成整个匹配的过程。和已有的方法比较,本算法具有良好的準确度和效率,试验结果表明该方法具有有效性和实用性。
本算法有以下几个方面的特点:首先,不需要专家经验或统计学习的方法确定每个指标的阈值。中误差範围只是由匹配的目标尺度决定,不受地图综合和製图方法的影响。其次,依据製图误差理论,可以适用于各种来源不同比例尺的地理数据。再次,算法从高信任度的匹配数据来推理相对信任度的数据,同时将低信任度交给用户互动,进一步提高了匹配的效率,更符合数据生产的过程。最后,本文的方法适用于严格的製图规範下的多尺度地理数据的匹配,不一定适用于没有按照製图规範製作的志愿者地理数据。志愿者地理信息作为空间数据的一个新的重要的来源,如何有效地整合志愿地理数据和传统的数据,是下一步研究的方向。