
搜寻问题就是找出与给定关键字值相对应的记录,或者说是确定在数据结构中不存在这样的记录。如果数据是自然的线性顺序(例如,字典中字的顺序),这就使研究相关的问题非常有意义,我们称之为範围搜寻。
基本介绍
- 中文名:範围搜寻
- 外文名:range searching
- 範围搜寻:找出与给定关键字值相对应的记录
- 条件:关键字指定要检索的包括範围
- 套用学科:计算机原理
- 套用:字典中字的顺序等
定义
搜寻问题就是找出与给定关键字值相对应的记录,或者说是确定在数据结构中不存在这样的记录。如果数据是自然的线性顺序(例如,字典中字的顺序),这就使研究相关的问题非常有意义,我们称之为範围搜寻(range searching)。
这个问题是定位的问题,并不是搜寻规定关键字值的单一记录,而是搜寻位于两个具体关键字限值之间的所有记录。
为了抽象地描述这个问题,我们假构想要表示的有序对 由key值和info值组成,我们希望在info值上实现任意操作Op:
由key值和info值组成,我们希望在info值上实现任意操作Op:
RangeSearch(L,U,S,Op):在每个info I 上执行Op操作,当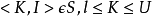 。
。
在普通的二分搜寻树中很容易实现範围搜寻。其基本的思想就是,从树中的一个节点开始,对存储在节点上的信息执行相应的操作,如果节点的关键字K在这个範围内;如果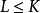 就在左子树中递归搜寻(因为在左子树中可能有该範围内的附加元素),如果
就在左子树中递归搜寻(因为在左子树中可能有该範围内的附加元素),如果 就在右子树中递归搜寻。
就在右子树中递归搜寻。
搜寻引擎
定义
搜寻引擎是指根据一定的策略,运用特定的电脑程式从网际网路上蒐集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索的相关信息传输到用户的系统。搜寻引擎包括全文索引、目录索引、元搜寻引擎、垂直搜寻引擎、集合式搜寻引擎、门户楷索引擎与免费连结列表等。
工作原理
第一步:爬行:搜寻引擎是通过运行一种特定规律的软体来跟蹤网页的连结,从一个连结追蹤到另外一个连结,就像蜘蛛在蜘蛛网上爬行一样,所以被称为“蜘蛛”,也被称为“机器人”。搜寻引擎“蜘蛛”在网际网路爬行时,它被设定了一定的规则,需要遵守某些命令或文本的规则。
第二步,抓取存储:搜寻引擎是通过“蜘蛛”跟蹤连结爬行到网页,并将爬行得来的数据存入原始页面资料库。其中的页面数据与用户浏览器得到的HTMI。是完全一样的。搜寻引擎“蜘蛛”在抓取页面时,也对内容做一定的重複性检测,一旦遇到权重很低的网站上有大量抄袭、採集或者複製的内容,很可能就不再爬行。
第三步,预处理:这是指搜寻引擎将“蜘蛛”抓取回来的页面进行各种步骤的预处理。
(1)提取文字;
(2)中文分词;
(3)去停词;
(4)消除嗓音;
(5)去重;
(6)正向索引;
(7)倒排索引;
(8)连结关係计算;
(9)特殊档案处理。
第四步,排名:用户在搜寻框输入关键字后,排名程式调用索引库数据,计算排名显示给用户,排名过程是与用户直接互动的。由于搜寻引擎获取的数据量庞大,搜寻引擎的排名规则通常根据日、周、月属性进行更新。